
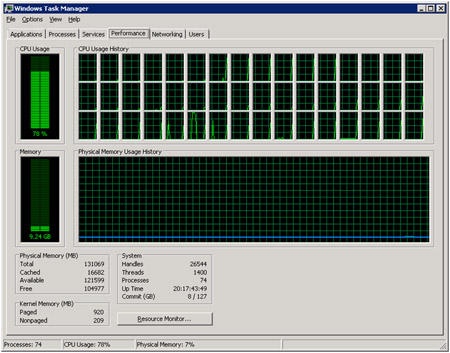
Spatial recently purchased an extreme piece of hardware to investigate the scalability of our multiprocessing infrastructures in both ACIS and CGM. This system has 48 processing units, 128 gigs of RAM, and a solid state hard-drive. (I did say extreme!)
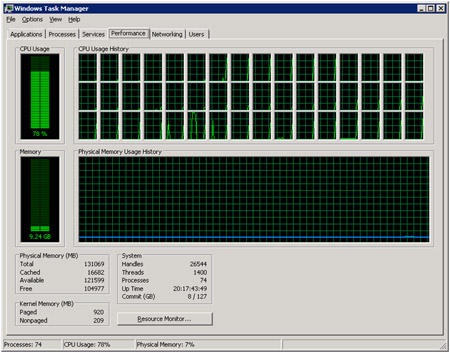
To showcase the potential of this beast I decided to focus on a common workflow, loading and visualizing models. This uses restore and facet functionality, which is apropos since both are candidates for future performance improvement projects. So the challenge became clear: to use the multi-threading capabilities in ACIS to restore, facet, and render models as quickly as possible.
For the purpose of this test I chose a fairly large assembly model that looks like a futuristic hover vehicle called Skywalker. This model, which came to us through a modeling contest, is underutilized in our demos because of its size and complexity. It simply takes too long to bring it up in an application. The mode contains 632 bodies using 132 megabytes of binary data. This was the perfect candidate for this experiment.
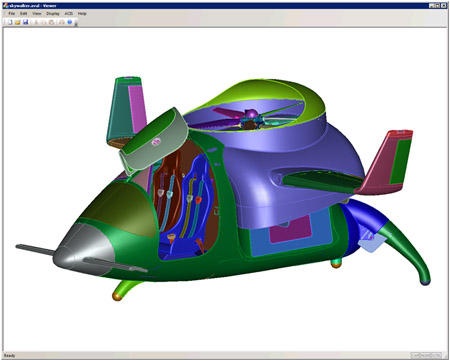
The mission begins with a simple and customizable ACIS-based viewer application that uses OpenGL for visualization. The workflow for this test is: restore, facet, and render. The render step is converting the facet data to OpenGL primitives and displaying them.
To better facilitate multi-threading in restore, I saved each body of the assembly separately, placing the individual data blocks end to end in the same file. In addition, I added the seek locations of each data block to a table that I placed at the beginning of the file. With this I can: load the table, seek to each location, and restore each body. Adding concurrency is then straightforward as each thread simply restores the body at the next available offset. Adding multi-threading to the facet step is also straightforward as the bodies of the assembly are independent of each other, a prerequisite for concurrent operations in thread-safe ACIS. We know this to be the case because each body was restored on its own, without having dependencies on other bodies.
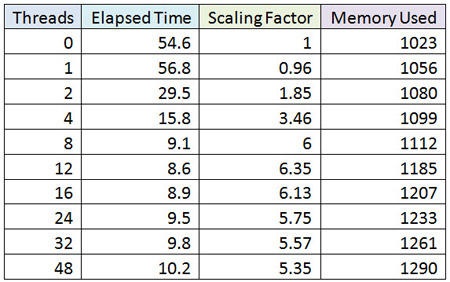
I proceeded to load the Skywalker model numerous times, varying the number of processors used by each run.
In recording the data:
- The Threads column is the number of threads used - one per processor, with zero indicating the normal serial flow using only the main process.
- The Time column reports the combined elapsed time for loading and faceting.
- The Scaling column reports the scaling factor in relation to the number of processors used.
- The Memory column reports the memory high-water mark in megabytes.
As the table below shows, the best performance was effectively reached by using only 12 of the available cores.
To better understand why the scaling diminished so quickly, I added timing logic to the relevant functionality and ran the tests again. The timing data exposed three main issues: threading overhead, poor data locality, and a "long pole in the tent". The threading overhead is well known to us: accessing values in thread-local-storage as opposed to directly adds a performance penalty. As do concurrent memory allocations, since the memory store as a single global resource is a choke point. Although we’ve diminished the impact with our custom memory manager, this can still contribute significantly to performance degradations.
The overhead of poor data locality is best thought of as a tax paid in relation to the size of the memory footprint. This is mainly caused by a less efficient use of cache as threads operate on data that is spread out over an increasingly wider address range. This reminds me of an experiment I did years ago, in which I was trying to measure the overhead of memory management. I modified ACIS code to pre-allocate all the memory needed to run a specific test. I then changed our internal allocator to simply hand back the next available space in the pre-allocated data store, and modified the de-allocator to do nothing. To my surprise, the test slowed down! The take-away was clear . . . it is more efficient to work on data that is close together.
The Skywalker assembly contained one body that was significantly more complex than the others. As a consequence, the restore and facet times were much higher for this particular body, than for the others. So much so, that all other bodies were completely processed by other threads - while one thread only worked on this one body. We call this the "long pole in the tent". Given infinite processing power, the best you can do is the time taken to compute the largest task.
So the lesson learned is simply this: don’t expect perfect scaling. The performance increases are nonetheless significant, and will continue to improve as technology advances. While individual processor performance is not increasing as quickly as it has in the past, the performances of other components are. Throughput and access times to both RAM and secondary storage have improved significantly, with multi-channel RAM and solid-sate hard drives. These hardware advances will continue to reduce the overheads of multiprocessing without requiring modifications in software. Additionally, we will learn from exercises such as this one and will continue to make improvements to our multiprocessing infrastructures.


.jpg?width=450&name=Application%20Lifecycle%20Management%20(1).jpg)














