

In my previous blog post I compared the different multi-processing technologies used in ACIS and CGM. The primary difference being that ACIS is based on a shared memory model, utilizing multiple threads in a single process while CGM is based on a distributed memory model, utilizing multiple processes with inter-process communications. This article will focus on ACIS, leaving CGM for next time.
ACIS is thread-safe. This is a major milestone in our quest to embrace the multi-core trend, which is on the verge of producing a true 16 core processor. Thirty-two and 64 CPU systems will soon be within reasonable reach. This capacity will allow our customers to pursue significant performance enhancements in their end-user applications with multi-processing.
Thread-safety is a prerequisite to concurrency, which provides true parallelism when paired with multi-processor/multi-core architectures. Here threads work concurrently to complete tasks in less time. The performance increase is usually described as a scaling factor with respect to the number of available cores. The goal of course is to achieve ideal scaling, representing an ideal use of available processing power.
Adding concurrency to your application deserves careful consideration, as it requires compute intensive workflows that meet certain criteria. The ability to break up the inputs into meaningful individual tasks, for them to be well balanced with roughly equal complexity, and without side effects when computed out of order, is important. The workflows should also be stable and well understood before they are considered.
 Global operations on multiple models (aka assembly modeling) provides good opportunities for parallelism because the models are typically independent of each other. This represents a single instruction – multiple data (SIMD) workflow, where operations have no affect on each other because of data independence. Loading and faceting of large assemblies are good examples, as are computing cross sections and collision detection.
Global operations on multiple models (aka assembly modeling) provides good opportunities for parallelism because the models are typically independent of each other. This represents a single instruction – multiple data (SIMD) workflow, where operations have no affect on each other because of data independence. Loading and faceting of large assemblies are good examples, as are computing cross sections and collision detection.
Watch this video of cross-sectioning an assembly. Here we slice an assembly multiple times, computing the intersections for each independent model concurrently. Computing 100 slices using 7 worker threads takes 8 seconds, and 32.6 seconds using normal serial execution. This represents a scaling factor of 4, whereas ideal scaling would have required the operation to complete in 4.6 seconds. Nonetheless, such performance improvements have a positive impact on the end-user experience.
Compute intensive operations on single models may also be candidates for parallelism. Here the parallel operations are performed on interconnected elements of a model. The challenge is decoupling the interdependencies to avoid unwanted interactions, which can lead to incorrect results, non-deterministic behavior, and even severe errors. The decoupling is accomplished by copying the required portions of the model into the context of the thread, thereby making the data independent. Performance gains are possible when the extra overhead of the copy operation is minimal with respect to the task computation time.
 Faceting a single body face-by-face in ACIS for example, can be accomplished more quickly using multiple threads. We must first deep copy each face into the context of the worker thread (i.e. its history stream), an efficient operation in ACIS. The copied face is then completely independent and can be freely accessed without affecting other threads. As a side effect, the independent faces are unaware of their surrounding faces since these were not copied. Generating water-tight facets without this adjacency information can be tricky, possibly making this operation a difficult one to parallelize to the extent that the results are fully equivalent to the serial operation.
Faceting a single body face-by-face in ACIS for example, can be accomplished more quickly using multiple threads. We must first deep copy each face into the context of the worker thread (i.e. its history stream), an efficient operation in ACIS. The copied face is then completely independent and can be freely accessed without affecting other threads. As a side effect, the independent faces are unaware of their surrounding faces since these were not copied. Generating water-tight facets without this adjacency information can be tricky, possibly making this operation a difficult one to parallelize to the extent that the results are fully equivalent to the serial operation.
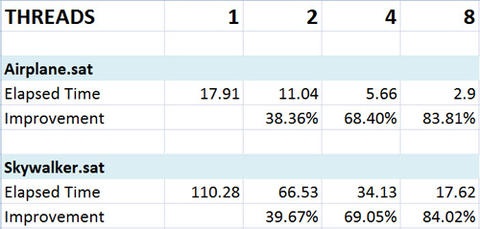
The following table shows the benefits of face-by-face faceting with multiple threads. The airplane assembly is roughly 40 MB in size, made up of 149 models. The Skywalker assembly is 240 MB in size, with 633 models.
In contrast to the faceting example, computing intersections of face pairs does not rely on adjacency information, making it an excellent candidate for single body parallelism. The faces and their supporting geometry are copied, making them independent. The intersections can then be computed in parallel. Before the results can be combined, they must first be merged into the context of the main thread. Merging, which is much faster than copying, is possible because the results are newly created and without interdependencies. (Computing intersections in parallel was the very first operation to use the multi-processing infrastructure in CGM.)
In our multi-threaded entity-point-distance API we compute (among other things) the entity on which the nearest point lies. This entity, a face, edge or vertex, is on the copy, not the source body. We therefore had to find a way to map it to the original, another tricky aspect of combining results. Fortunately the topological order is preserved in the copy process, which allows the use of the indices in the lists retrieved with the topological query functions (e.g. api_get_edges).
My intent was not to make the use of threads seem overly complex and riddled with obstacles, but instead to share some of our experiences, good and bad. The thread-safe ACIS modeler provides the infrastructure and tools needed to add multi-processing to your applications. It’s up to you to take advantage of it. The task may not always be trivial, and you may encounter both good and bad experiences of your own, but the results are usually well worth the efforts.
What are some of your experiences with adding multi-processing to your applications?
Learn More about ACIS in our Webinars


.jpg?width=450&name=Application%20Lifecycle%20Management%20(1).jpg)














